Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM
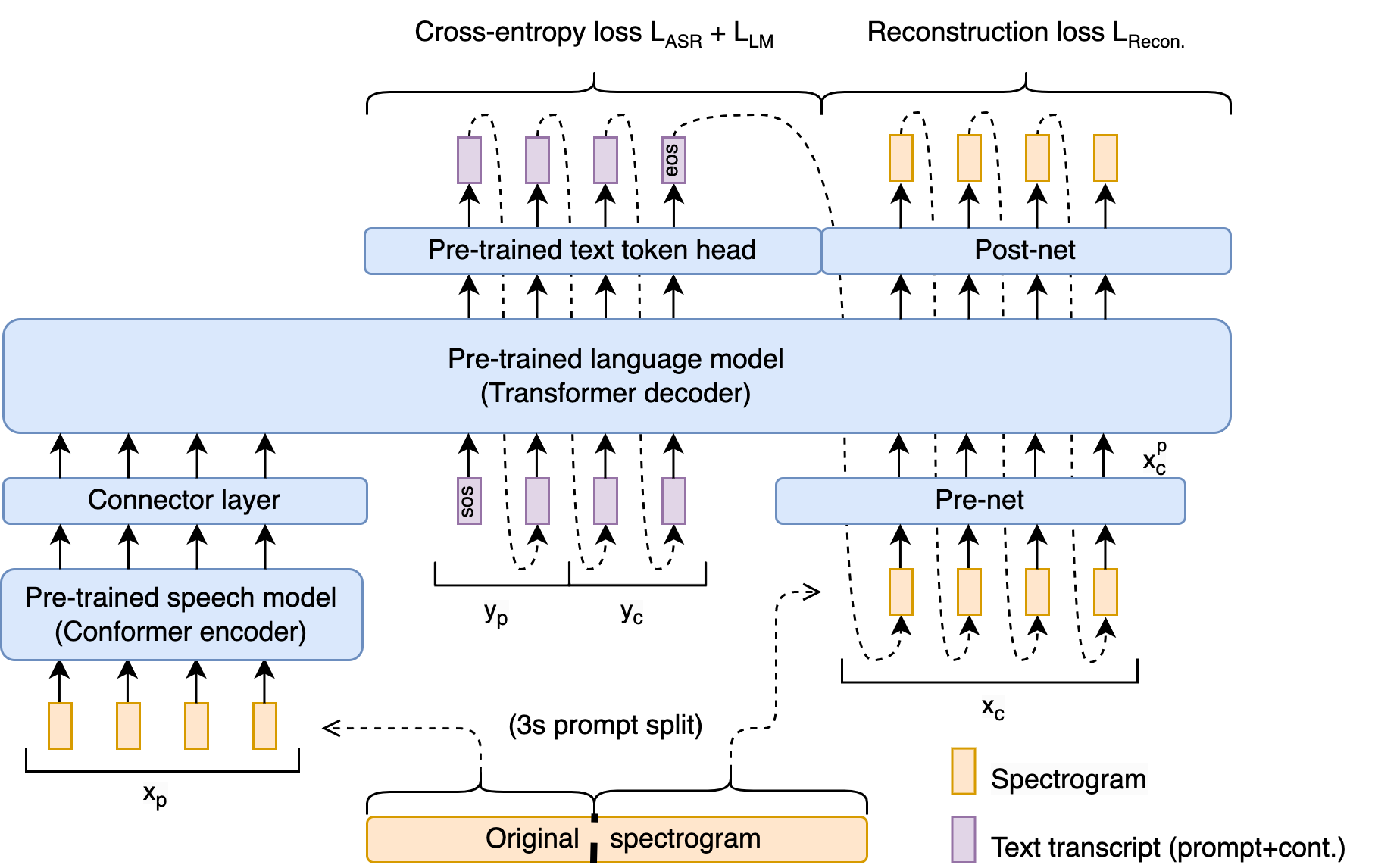
We present a novel approach to adapting pre-trained large language models (LLMs) to perform question answering (QA) and speech continuation. By endowing the LLM with a pre-trained speech encoder, our model becomes able to take speech inputs and generate speech outputs. The entire system is trained end-to-end and operates directly on spectrograms, simplifying our architecture. Key to our approach is a training objective that jointly supervises speech recognition, text continuation, and speech synthesis using only paired speech-text pairs, enabling a `cross-modal' chain-of-thought within a single decoding pass. Our method surpasses existing spoken language models in speaker preservation and semantic coherence. Furthermore, the proposed model improves upon direct initialization in retaining the knowledge of the original LLM as demonstrated through spoken QA datasets.
LLama Questions dataset is available at this github repository.
Model
The first audio column labeled Librispeech continuation
| Prompt | Spectron | GSLM | AudioLm | TWIST | SpeechGPT |
|---|---|---|---|---|---|
The first audio column labeled LLama questions
| Question | Spectron | GSLM | AudioLM | TWIST | SpeechGPT |
|---|---|---|---|---|---|
The first audio column labeled Spoken WebQuestions
| Question | Spectron | GSLM | AudioLM | TWIST | SpeechGPT |
|---|---|---|---|---|---|